核心数据结构
核心数据结构是在通道使用过程中定义的特殊DTO结构,通常为一个Java的Class文件定义。
具体哪个抽象类包含了这些数据结构,可参考:OX-005 - 通道架构
1. Identity标识选择器
在I_SERVICE中,开发人员配置的每一条服务记录都是和 identifier(标识符)执行绑定,这种绑定在容器启动时就已经决定,不可更改。如:一条 SERVICE 绑定了 ci.database 表示这个服务是和数据库类配置项绑定的服务。
整个 Origin X 在建模过程中,每个模型对应唯一的 identifier,而不同的模型对应的底层存储表会有所区别。如:
| 模型 | 标识符 | 数据表 |
|---|---|---|
| 配置项顶层模型 | ci.device | CI_DEVICE |
| 数据库模型 | ci.database | CI_DEVICE, CI_DATABASE |
这种情况下,如果I_SERVICE配置绑定了某个标识符,那么该服务访问的底层表就固定了——但是,这不能满足业务场景中的某些需求,如当前服务绑定的是顶层模型ci.device,而最终接口需要访问的是确切的子类,如 ci.database 和 ci.network,这种情况下就需要使用标识选择器——根据不同输入数据选择不同的标识符而改变服务的真正访问数据表,执行动态访问。
2. DualMapping映射器
2.1 基本配置
映射器配置主要定义了字段的映射关系,而编程过程需要配合DictFabric / FieldMapper来工作。如下边格式:
{
"name": "xxx",
"email": "xxx@xxx.com"
}
如果搭载上映射器的配置过后,可以在输入Before、输出After、环绕Around三个阶段开启映射器,只是需要注意,单独使用不同阶段的映射过程中,配置会有所区别,参考下图:
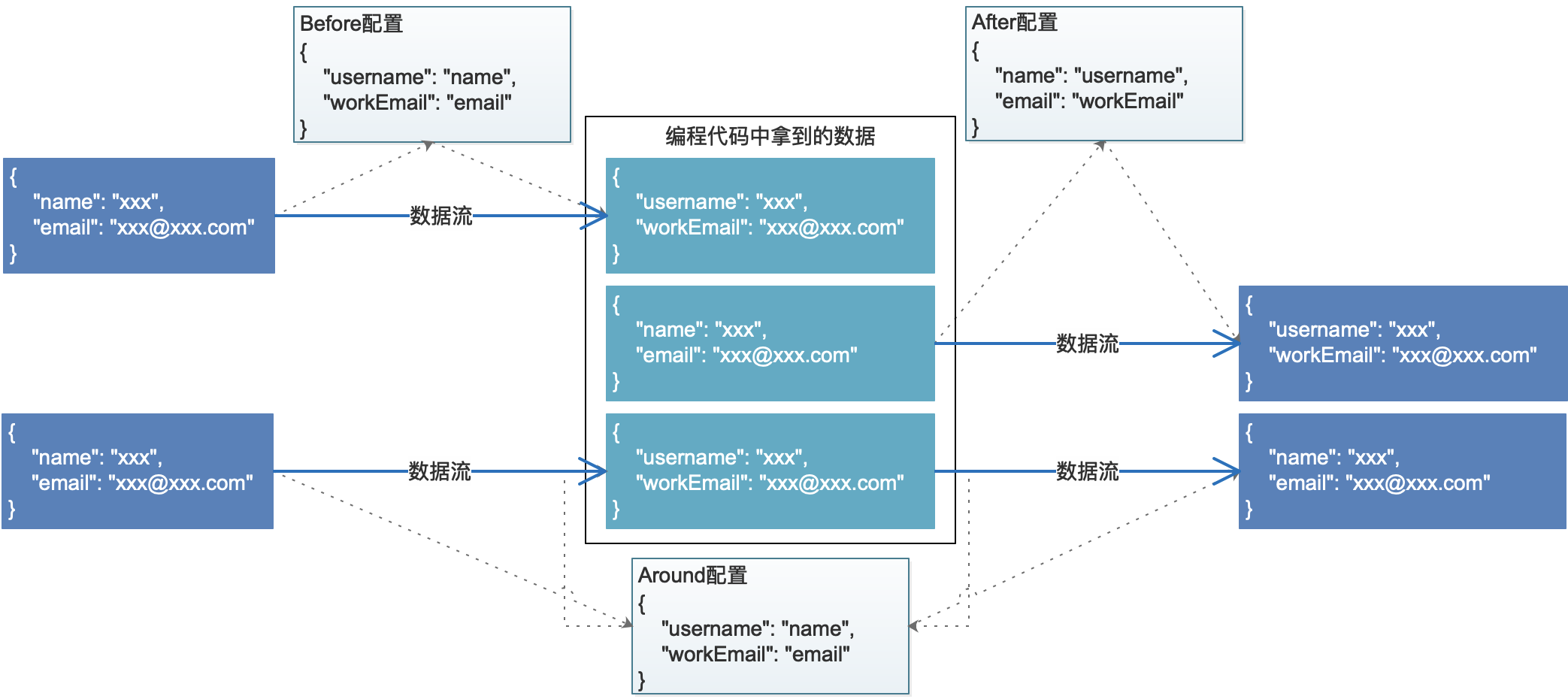
开发人员必须清楚编程代码中拿到的数据会受到 DualMapping 配置的影响!
这里需要说明的几点如下:
- 上述映射转换是配置型的,配置了映射模式过后,数据执行自动转换。
- 转换过程中,保持一个原则——不论Before、After、Around三种模式,编程代码中拿到的数据永远维持配置过程中的左值,Json配置中的键。
- 如果需要在编程过程中手动转换,则需要调用
this.vector()方法获取FieldMapper来执行手动转换。
其余的内容不在这里做说明,开发过程中请开发人员自己体会。
2.2 父子级结构
DualMapping的配置是整体映射配置,每一部分(仅包含字符串键值对)在Java代码中是一个DualItem,而DualMapping是支持父子结构的,配合前一个章节中的表示转换器,当identifier发生改变的时候,可以切换不同的DualItem。如:
{
"name": "username",
"email": "workEmail",
"ci.database": {
"name": "databaseName",
"username": "account"
}
}
在上述格式中,存在两个DualItem,它的整体结构如下:
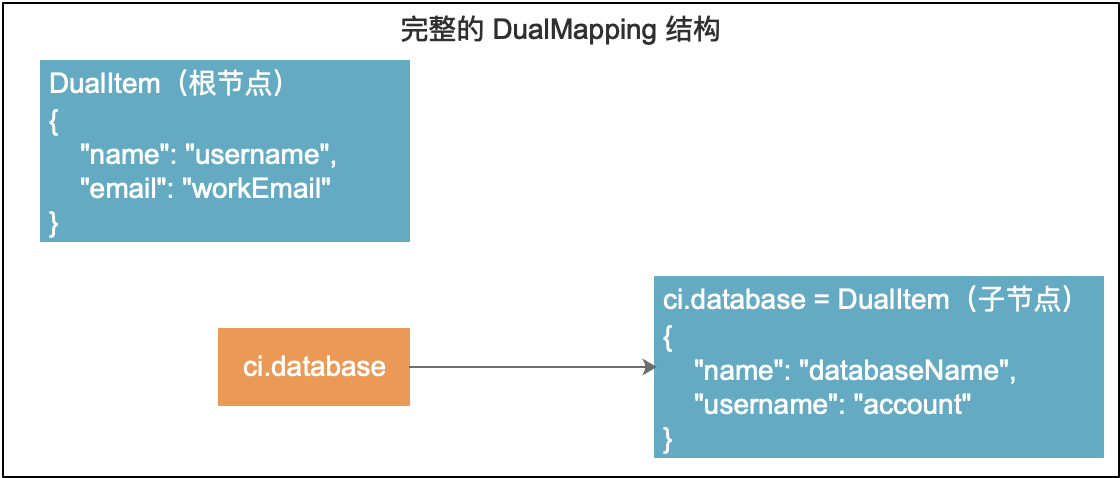
在这个配置中,合计配置了两个 DualItem,其中一个是根节点,另外一个是子节点,对应的标识符是:ci.database,编程中可以通过下边的方式获取:
// 读取根节点的 mapping 配置
final DualItem root = this.mapping().child();
// 读取 `ci.database` 节点的 mapping 配置
final DualItem child = this.mapping().child("ci.database");
更加详细的 mapping 配置可参考:OI-004 业务层 Mapping
3. XHeader
XHeader是当前容器中的核心维度数据,它主要存储了下边的数据信息:
| 变量 | 请求头 | 含义 |
|---|---|---|
| sigma | X-Sigma | 抽象多租户环境标识,目前版本 APP_ID 与之绑定 |
| appId | X-App-Id | 多应用环境的应用 ID,长远考虑 sigma 范围大于 appId |
| appKey | X-App-Key | 多应用环境的特殊加密应用 ID,和 appId 一一绑定 |
| language | X-Lang | 多语言环境标识,目前暂时只支持 cn |
编程过程中,通常会读取 sigma(zero extension中大部分数据都是带有 sigma 维度的,如目前的 xx 客户就拥有唯一的一个 sigma 值)。
4. DictFabric字典翻译器
在旧版本中的通道中,AbstractComponent 可以拿到的是原生 Dict 的字典定义数据,而新版本直接读取 DictFabric 的字典翻译器(更简单),关于Dict的原理可以参考:OI-005 业务层 Dict,开发人员需要清楚获取字典翻译器的核心 API(四种字典翻译器)。字典翻译器包含三个核心部分:
- 字典数据
ConcurrentMap<String,JsonArray>(根据定义读取的字典信息)。 - 字典消费定义
ConcurrentMap<String, DictEpsilon>。 - 带映射的字典定义,绑定了
DualItem和DataAtom模型的字典定义。
它的整体结构如下:
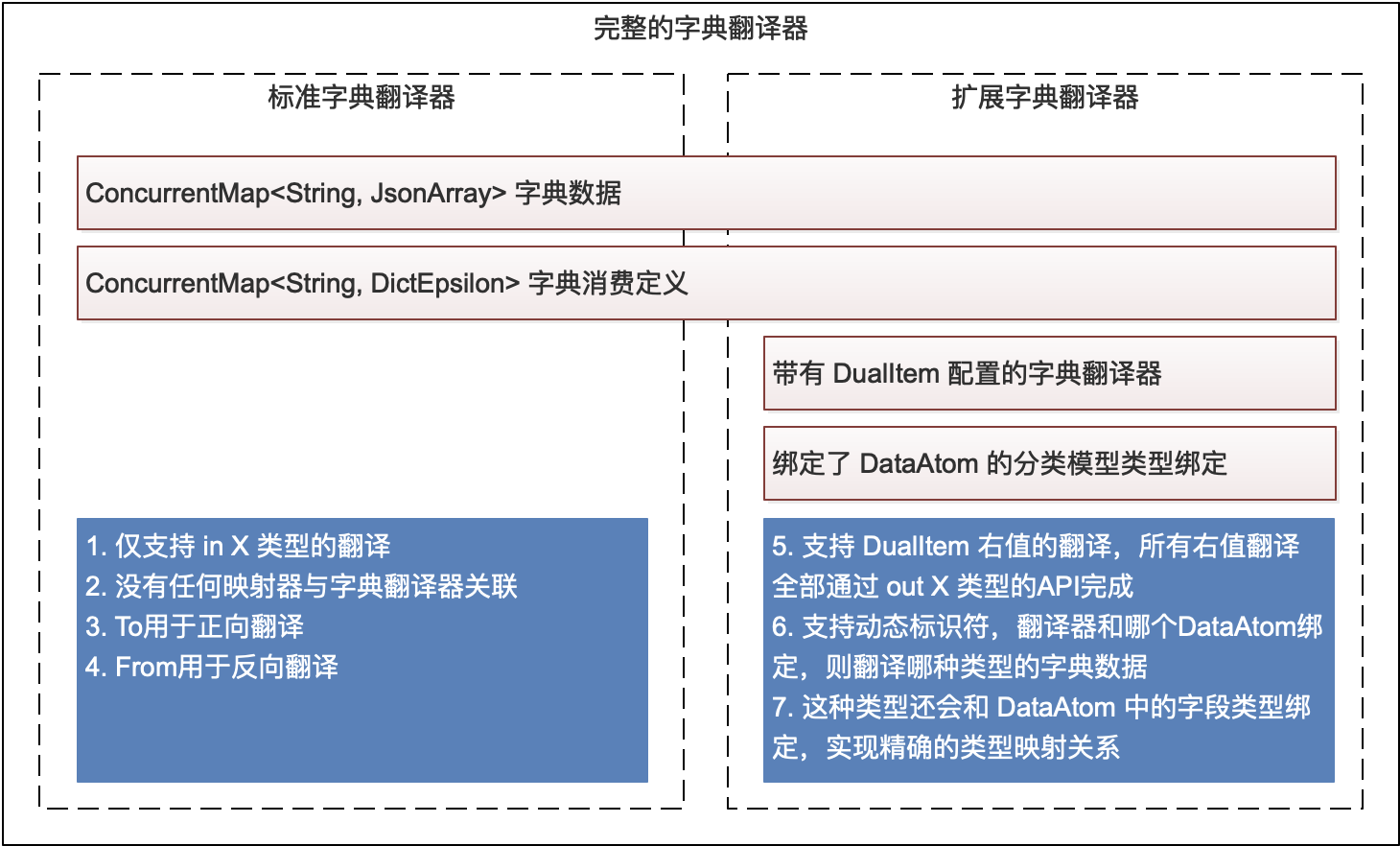
根据上边的结构图,字典翻译器主要分为两种:
- 标准字典翻译器(不包含映射 DualItem 配置)
- 扩展字典翻译器(和 DualItem 配置绑定)
参考下边的代码:
// 第一类:字典翻译器(最常用)
// 1)如果未配置 DualMapping,那么就是标准字典翻译器
// 2)如果配置了 DualMapping,那么就是扩展字典翻译器
final DictFabric fabric = this.fabric;
// 第二类:标准字典翻译器(测试专用):该字典翻译器不绑定 DualItem
final JsonObject configJson = ...;
final DictFabric fabric = this.fabric(configJson);
/**
* 1)以上两种字典翻译器直接在抽象层可用,AbstractComponent 自带
* 2)下边两种字典翻译器属于具像层的变幻,AbstractAdaptor 以及子类可用
* 3)下边两类都是从第一类变幻而来,
* - 第一类是标准字典翻译器,那么构造的也是标准字典翻译器
* - 第一类是扩展字典翻译器,那么构造的就是扩展字典翻译器。
**/
// 第三类:构造和 DataAtom 绑定的字典翻译器(静态定义的 DataAtom)
final DictFabric fabric = this.fabric();
// 第四类:构造和输入 DataAtom 绑定的字典翻译器(动态定义的 DataAtom)
final DataAtom atom = ...;
final DictFabric fabric = this.fabric(atom);
5. Database数据库定义
zero 标准的数据库定义,定义了数据库配置,结构参考vertx-jooq.yml中的配置数据。
6. FieldMapper字段转换器
如果第二章节中的DualMapping映射器无法满足字段映射需求时,开发人员可以直接获取FieldMapper实现纯字段转换功能,它的获取流程如下:
// 读取 FieldMapper 引用
final FieldMapper mapper = this.vector();
7. DataAtom/Switcher 模型定义
前文中已经提到过,每一个I_SERVICE都定义了模型的标识符(identifier),那么DataAtom就是模型访问中最核心的内容:元数据定义,它主要包括:
- 当前模型的名空间、名称、标识符、标识规则。
- 模型下边所有的字段信息。
- 模型关联的所有底层表结构。
- 表所对应的字段、约束、主键、唯一键、索引信息。
在访问配置项数据库时,完整步骤一般如下:
- 根据是否配置了标识规则选择器,拿到最终的 identifier。
- 根据 identifier 和 XHeader 中的多应用环境拿到当前应用的 DataAtom。
- 使用 DataAtom 去构造 Record。
- 调用 AoDao 操作 Record 实现数据库(Database配置)的增删查改。
通道中已经拿到了 DataAtom 后,开发人员就只需要关注第三步填充 Record 即可,而 Switcher 在通道中是 DataAtom 的辅助类,它可以拿到单一的 DataAtom,也可以拿到一组完整的 DataAtom(操作多个模型时使用),而开发人员不需要关心 Switcher,除非是高级开发,因为他们可以直接通过下边代码示例拿到自己想要的 DataAtom。
参考下边代码拿到 DataAtom 相关引用:
// 静态配置的 DataAtom 直接获取,
// ------------------- 定义于 AbstractAdaptor
// 和 I_SERVICE 中配置的 identifier 绑定
final DataAtom atom = this.atom();
// 下边的两种方式注意异步读取!!!
// 动态单记录 DataAtom 获取
// ------------------- 定义于 AbstractHData 中
// 单记录操作
final JsonObject data = ...;
return this.atom(data).compose(atom -> {
// 这里得到的 atom 就是 DataAtom
return Ux.future(...); // 返回最终数据
});
// 动态多记录 DataAtom 获取,
// ------------------- 定义于 AbstractHBatch 中
// 批量操作
final JsonArray data = ...;
return this.atom(data).compose(groupSet -> {
// 1. groupSet 是一个 Set<DataGroup> 类型(集合)
// 2. 每一个集合包含了两部分内容:
// - DataAtom:当前这一组数据的 DataAtom
// - JsonArray:当前这组数据
return Ux.future(...); // 返回最终数据
});
8. AoDao数据库访问器
通常AoDao是和当前的DataAtom绑定的,但为了实现可动态化的标识规则选择,所以AoDao是可以切换访问的模型标识符的,注意:模型标识符的转换意味着底层访问数据表会发生变化。
参考下边代码拿到 AoDao 数据访问器引用:
// ----------- 定义于 AbstractAdaptor
/* AoDao 的获取:静态标识 */
final AoDao dao = this.dao();
/* 按元数据定义的 AoDao 的获取:动态标识 */
final DataAtom atom = ...;
final AoDao dao = this.dao(atom);
// ----------- 定义于 AbstractHData
/* 按数据录入的 AoDao 的获取:异步、动态标识 */
final JsonObject data = ...;
return this.dao(data).compose(dao -> {
// 这里拿到的 AoDao 就是可操作当前记录专用的 AoDao引用
return Ux.future(...);
});
9. Integration集成配置定义
zero 标准的集成配置定义,参考:runtime/external/integration.json中的定义。
10. Mission任务配置定义
zero 标准的任务配置定义,无静态 Json 结构,可参考 Mission 的源代码。